使用线程
放在十年前,多线程编程可能还是一个少数人才掌握的核心概念,但是在今天,随着编程语言的不断发展,多线程、多协程、Actor 等并发编程方式已经深入人心,同时多线程编程的门槛也在不断降低,本章节我们来看看在 Rust 中该如何使用多线程。
多线程编程的风险
由于多线程的代码是同时运行的,因此我们无法保证线程间的执行顺序,这会导致一些问题:
- 竞态条件(race conditions),多个线程以非一致性的顺序同时访问数据资源
- 死锁(deadlocks),两个线程都想使用某个资源,但是又都在等待对方释放资源后才能使用,结果最终都无法继续执行
- 一些因为多线程导致的很隐晦的 BUG,难以复现和解决
虽然 Rust 已经通过各种机制减少了上述情况的发生,但是依然无法完全避免上述情况,因此我们在编程时需要格外的小心,同时本书也会列出多线程编程时常见的陷阱,让你提前规避可能的风险。
创建线程
使用 thread::spawn 可以创建线程:
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
}有几点值得注意:
- 线程内部的代码使用闭包来执行
main线程一旦结束,程序就立刻结束,因此需要保持它的存活,直到其它子线程完成自己的任务thread::sleep会让当前线程休眠指定的时间,随后其它线程会被调度运行(上一节并发与并行中有简单介绍过),因此就算你的电脑只有一个 CPU 核心,该程序也会表现的如同多 CPU 核心一般,这就是并发!
来看看输出:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 4 from the main thread!
hi number 5 from the spawned thread!
如果多运行几次,你会发现好像每次输出会不太一样,因为:虽说线程往往是轮流执行的,但是这一点无法被保证!线程调度的方式往往取决于你使用的操作系统。总之,千万不要依赖线程的执行顺序。
等待子线程的结束
上面的代码你不但可能无法让子线程从 1 顺序打印到 10,而且可能打印的数字会变少,因为主线程会提前结束,导致子线程也随之结束,更过分的是,如果当前系统繁忙,甚至该子线程还没被创建,主线程就已经结束了!
因此我们需要一个方法,让主线程安全、可靠地等所有子线程完成任务后,再 kill self:
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..5 {
println!("hi number {} from the spawned thread!", i);
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {} from the main thread!", i);
thread::sleep(Duration::from_millis(1));
}
}通过调用 handle.join,可以让当前线程阻塞,直到它等待的子线程的结束,在上面代码中,由于 main 线程会被阻塞,因此它直到子线程结束后才会输出自己的 1..5:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
以上输出清晰的展示了线程阻塞的作用,如果你将 handle.join 放置在 main 线程中的 for 循环后面,那就是另外一个结果:两个线程交替输出。
在线程闭包中使用 move
在闭包章节中,有讲过 move 关键字在闭包中的使用可以让该闭包拿走环境中某个值的所有权,同样地,你可以使用 move 来将所有权从一个线程转移到另外一个线程。
首先,来看看在一个线程中直接使用另一个线程中的数据会如何:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
}以上代码在子线程的闭包中捕获了环境中的 v 变量,来看看结果:
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {:?}", v);
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {:?}", v);
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
其实代码本身并没有什么问题,问题在于 Rust 无法确定新的线程会活多久(多个线程的结束顺序并不是固定的),所以也无法确定新线程所引用的 v 是否在使用过程中一直合法:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {:?}", v);
});
drop(v); // oh no!
handle.join().unwrap();
}大家要记住,线程的启动时间点和结束时间点是不确定的,因此存在一种可能,当主线程执行完, v 被释放掉时,新的线程很可能还没有结束甚至还没有被创建成功,此时新线程对 v 的引用立刻就不再合法!
好在报错里进行了提示:to force the closure to take ownership of v (and any other referenced variables), use the `move` keyword,让我们使用 move 关键字拿走 v 的所有权即可:
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {:?}", v);
});
handle.join().unwrap();
// 下面代码会报错borrow of moved value: `v`
// println!("{:?}",v);
}如上所示,很简单的代码,而且 Rust 的所有权机制保证了数据使用上的安全:v 的所有权被转移给新的线程后,main 线程将无法继续使用:最后一行代码将报错。
线程是如何结束的
之前我们提到 main 线程是程序的主线程,一旦结束,则程序随之结束,同时各个子线程也将被强行终止。那么有一个问题,如果父线程不是 main 线程,那么父线程的结束会导致什么?自生自灭还是被干掉?
在系统编程中,操作系统提供了直接杀死线程的接口,简单粗暴,但是 Rust 并没有提供这样的接口,原因在于,粗暴地终止一个线程可能会导致资源没有释放、状态混乱等不可预期的结果,一向以安全自称的 Rust,自然不会砸自己的饭碗。
那么 Rust 中线程是如何结束的呢?答案很简单:线程的代码执行完,线程就会自动结束。但是如果线程中的代码不会执行完呢?那么情况可以分为两种进行讨论:
- 线程的任务是一个循环 IO 读取,任务流程类似:IO 阻塞,等待读取新的数据 -> 读到数据,处理完成 -> 继续阻塞等待 ··· -> 收到 socket 关闭的信号 -> 结束线程,在此过程中,绝大部分时间线程都处于阻塞的状态,因此虽然看上去是循环,CPU 占用其实很小,也是网络服务中最最常见的模型
- 线程的任务是一个循环,里面没有任何阻塞,包括休眠这种操作也没有,此时 CPU 很不幸的会被跑满,而且你如果没有设置终止条件,该线程将持续跑满一个 CPU 核心,并且不会被终止,直到
main线程的结束
第一情况很常见,我们来模拟看看第二种情况:
use std::thread;
use std::time::Duration;
fn main() {
// 创建一个线程A
let new_thread = thread::spawn(move || {
// 再创建一个线程B
thread::spawn(move || {
loop {
println!("I am a new thread.");
}
})
});
// 等待新创建的线程执行完成
new_thread.join().unwrap();
println!("Child thread is finish!");
// 睡眠一段时间,看子线程创建的子线程是否还在运行
thread::sleep(Duration::from_millis(100));
}以上代码中,main 线程创建了一个新的线程 A,同时该新线程又创建了一个新的线程 B,可以看到 A 线程在创建完 B 线程后就立即结束了,而 B 线程则在不停地循环输出。
从之前的线程结束规则,我们可以猜测程序将这样执行:A 线程结束后,由它创建的 B 线程仍在疯狂输出,直到 main 线程在 100 毫秒后结束。如果你把该时间增加到几十秒,就可以看到你的 CPU 核心 100% 的盛况了-,-
多线程的性能
下面我们从多个方面来看看多线程的性能大概是怎么样的。
创建线程的性能
据不精确估算,创建一个线程大概需要 0.24 毫秒,随着线程的变多,这个值会变得更大,因此线程的创建耗时是不可忽略的,只有当真的需要处理一个值得用线程去处理的任务时,才使用线程,一些鸡毛蒜皮的任务,就无需创建线程了。
创建多少线程合适
因为 CPU 的核心数限制,当任务是 CPU 密集型时,就算线程数超过了 CPU 核心数,也并不能帮你获得更好的性能,因为每个线程的任务都可以轻松让 CPU 的某个核心跑满,既然如此,让线程数等于 CPU 核心数是最好的。
但是当你的任务大部分时间都处于阻塞状态时,就可以考虑增多线程数量,这样当某个线程处于阻塞状态时,会被切走,进而运行其它的线程,典型就是网络 IO 操作,我们可以为每一个进来的用户连接创建一个线程去处理,该连接绝大部分时间都是处于 IO 读取阻塞状态,因此有限的 CPU 核心完全可以处理成百上千的用户连接线程,但是事实上,对于这种网络 IO 情况,一般都不再使用多线程的方式了,毕竟操作系统的线程数是有限的,意味着并发数也很容易达到上限,而且过多的线程也会导致线程上下文切换的代价过大,使用 async/await 的 M:N 并发模型,就没有这个烦恼。
多线程的开销
下面的代码是一个无锁实现(CAS)的 Hashmap 在多线程下的使用:
#![allow(unused)]
fn main() {
for i in 0..num_threads {
let ht = Arc::clone(&ht);
let handle = thread::spawn(move || {
for j in 0..adds_per_thread {
let key = thread_rng().gen::<u32>();
let value = thread_rng().gen::<u32>();
ht.set_item(key, value);
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
}按理来说,既然是无锁实现了,那么锁的开销应该几乎没有,性能会随着线程数的增加接近线性增长,但是真的是这样吗?
下图是该代码在 48 核机器上的运行结果:
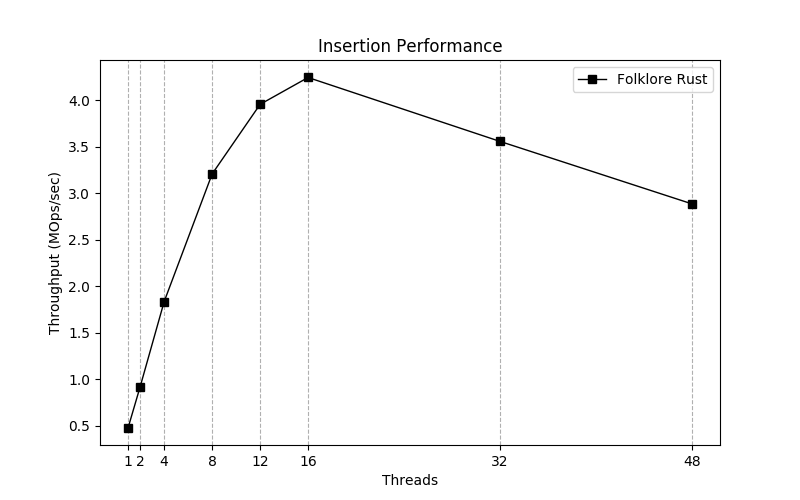
从图上可以明显的看出:吞吐并不是线性增长,尤其从 16 核开始,甚至开始肉眼可见的下降,这是为什么呢?
限于书本的篇幅有限,我们只能给出大概的原因:
- 虽然是无锁,但是内部是 CAS 实现,大量线程的同时访问,会让 CAS 重试次数大幅增加
- 线程过多时,CPU 缓存的命中率会显著下降,同时多个线程竞争一个 CPU Cache-line 的情况也会经常发生
- 大量读写可能会让内存带宽也成为瓶颈
- 读和写不一样,无锁数据结构的读往往可以很好地线性增长,但是写不行,因为写竞争太大
总之,多线程的开销往往是在锁、数据竞争、缓存失效上,这些限制了现代化软件系统随着 CPU 核心的增多性能也线性增加的野心。
线程屏障(Barrier)
在 Rust 中,可以使用 Barrier 让多个线程都执行到某个点后,才继续一起往后执行:
use std::sync::{Arc, Barrier};
use std::thread;
fn main() {
let mut handles = Vec::with_capacity(6);
let barrier = Arc::new(Barrier::new(6));
for _ in 0..6 {
let b = barrier.clone();
handles.push(thread::spawn(move|| {
println!("before wait");
b.wait();
println!("after wait");
}));
}
for handle in handles {
handle.join().unwrap();
}
}上面代码,我们在线程打印出 before wait 后增加了一个屏障,目的就是等所有的线程都打印出before wait后,各个线程再继续执行:
before wait
before wait
before wait
before wait
before wait
before wait
after wait
after wait
after wait
after wait
after wait
after wait
线程局部变量(Thread Local Variable)
对于多线程编程,线程局部变量在一些场景下非常有用,而 Rust 通过标准库和三方库对此进行了支持。
标准库 thread_local
使用 thread_local 宏可以初始化线程局部变量,然后在线程内部使用该变量的 with 方法获取变量值:
#![allow(unused)]
fn main() {
use std::cell::RefCell;
use std::thread;
thread_local!(static FOO: RefCell<u32> = RefCell::new(1));
FOO.with(|f| {
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 2;
});
// 每个线程开始时都会拿到线程局部变量的FOO的初始值
let t = thread::spawn(move|| {
FOO.with(|f| {
assert_eq!(*f.borrow(), 1);
*f.borrow_mut() = 3;
});
});
// 等待线程完成
t.join().unwrap();
// 尽管子线程中修改为了3,我们在这里依然拥有main线程中的局部值:2
FOO.with(|f| {
assert_eq!(*f.borrow(), 2);
});
}上面代码中,FOO 即是我们创建的线程局部变量,每个新的线程访问它时,都会使用它的初始值作为开始,各个线程中的 FOO 值彼此互不干扰。注意 FOO 使用 static 声明为生命周期为 'static 的静态变量。
可以注意到,线程中对 FOO 的使用是通过借用的方式,但是若我们需要每个线程独自获取它的拷贝,最后进行汇总,就有些强人所难了。
你还可以在结构体中使用线程局部变量:
use std::cell::RefCell;
struct Foo;
impl Foo {
thread_local! {
static FOO: RefCell<usize> = RefCell::new(0);
}
}
fn main() {
Foo::FOO.with(|x| println!("{:?}", x));
}或者通过引用的方式使用它:
#![allow(unused)]
fn main() {
use std::cell::RefCell;
use std::thread::LocalKey;
thread_local! {
static FOO: RefCell<usize> = RefCell::new(0);
}
struct Bar {
foo: &'static LocalKey<RefCell<usize>>,
}
impl Bar {
fn constructor() -> Self {
Self {
foo: &FOO,
}
}
}
}三方库 thread-local
除了标准库外,一位大神还开发了 thread-local 库,它允许每个线程持有值的独立拷贝:
#![allow(unused)]
fn main() {
use thread_local::ThreadLocal;
use std::sync::Arc;
use std::cell::Cell;
use std::thread;
let tls = Arc::new(ThreadLocal::new());
let mut v = vec![];
// 创建多个线程
for _ in 0..5 {
let tls2 = tls.clone();
let handle = thread::spawn(move || {
// 将计数器加1
// 请注意,由于线程 ID 在线程退出时会被回收,因此一个线程有可能回收另一个线程的对象
// 这只能在线程退出后发生,因此不会导致任何竞争条件
let cell = tls2.get_or(|| Cell::new(0));
cell.set(cell.get() + 1);
});
v.push(handle);
}
for handle in v {
handle.join().unwrap();
}
// 一旦所有子线程结束,收集它们的线程局部变量中的计数器值,然后进行求和
let tls = Arc::try_unwrap(tls).unwrap();
let total = tls.into_iter().fold(0, |x, y| {
// 打印每个线程局部变量中的计数器值,发现不一定有5个线程,
// 因为一些线程已退出,并且其他线程会回收退出线程的对象
println!("x: {}, y: {}", x, y.get());
x + y.get()
});
// 和为5
assert_eq!(total, 5);
}该库不仅仅使用了值的拷贝,而且还能自动把多个拷贝汇总到一个迭代器中,最后进行求和,非常好用。
用条件控制线程的挂起和执行
条件变量(Condition Variables)经常和 Mutex 一起使用,可以让线程挂起,直到某个条件发生后再继续执行:
use std::thread;
use std::sync::{Arc, Mutex, Condvar};
fn main() {
let pair = Arc::new((Mutex::new(false), Condvar::new()));
let pair2 = pair.clone();
thread::spawn(move|| {
let (lock, cvar) = &*pair2;
let mut started = lock.lock().unwrap();
println!("changing started");
*started = true;
cvar.notify_one();
});
let (lock, cvar) = &*pair;
let mut started = lock.lock().unwrap();
while !*started {
started = cvar.wait(started).unwrap();
}
println!("started changed");
}上述代码流程如下:
main线程首先进入while循环,调用wait方法挂起等待子线程的通知,并释放了锁started- 子线程获取到锁,并将其修改为
true,然后调用条件变量的notify_one方法来通知主线程继续执行
只被调用一次的函数
有时,我们会需要某个函数在多线程环境下只被调用一次,例如初始化全局变量,无论是哪个线程先调用函数来初始化,都会保证全局变量只会被初始化一次,随后的其它线程调用就会忽略该函数:
use std::thread;
use std::sync::Once;
static mut VAL: usize = 0;
static INIT: Once = Once::new();
fn main() {
let handle1 = thread::spawn(move || {
INIT.call_once(|| {
unsafe {
VAL = 1;
}
});
});
let handle2 = thread::spawn(move || {
INIT.call_once(|| {
unsafe {
VAL = 2;
}
});
});
handle1.join().unwrap();
handle2.join().unwrap();
println!("{}", unsafe { VAL });
}代码运行的结果取决于哪个线程先调用 INIT.call_once (虽然代码具有先后顺序,但是线程的初始化顺序并无法被保证!因为线程初始化是异步的,且耗时较久),若 handle1 先,则输出 1,否则输出 2。
call_once 方法
执行初始化过程一次,并且只执行一次。
如果当前有另一个初始化过程正在运行,线程将阻止该方法被调用。
当这个函数返回时,保证一些初始化已经运行并完成,它还保证由执行的闭包所执行的任何内存写入都能被其他线程在这时可靠地观察到。
总结
Rust 的线程模型是 1:1 模型,因为 Rust 要保持尽量小的运行时。
我们可以使用 thread::spawn 来创建线程,创建出的多个线程之间并不存在执行顺序关系,因此代码逻辑千万不要依赖于线程间的执行顺序。
main 线程若是结束,则所有子线程都将被终止,如果希望等待子线程结束后,再结束 main 线程,你需要使用创建线程时返回的句柄的 join 方法。
在线程中无法直接借用外部环境中的变量值,因为新线程的启动时间点和结束时间点是不确定的,所以 Rust 无法保证该线程中借用的变量在使用过程中依然是合法的。你可以使用 move 关键字将变量的所有权转移给新的线程,来解决此问题。
父线程结束后,子线程仍在持续运行,直到子线程的代码运行完成或者 main 线程的结束。